Alta disponibilidad de ficheros en Rocky Linux con GlusterFS
Hace tiempo que no hablamos de los clústeres, así que, para solventarlo, en la entrada de hoy vamos a ver como crear y configurar un clúster en alta disponibilidad con GlusterFS, para un recurso de ficheros, utilizando la distribución Rocky Linux
![]()
¿Qué es GlusterFS?
GlusterFS es un sistema de archivos distribuido. Permite el almacenamiento de gran cantidad de datos distribuidos en clústeres de servidores, con una disponibilidad muy alta, por lo menos en teoría.
Los clientes pueden acceder a los datos a través del cliente glusterfs o el comando de montaje.
GlusterFS puede operar en dos formas:
- Modo replicado: cada nodo del clúster tiene todos los datos.
- Modo distribuido: sin redundancia de datos. Si falla uno nodo de almacenamiento, los datos del nodo fallido ser pierden.
Ambos modos se pueden usar juntos para proporcionar un sistema de archivos replicado y distribuido, siempre que tengamos la cantidad correcta de servidores.
Los datos se almacenan dentro de “bricks”, esto es, ladrillos.
Un “Brick” o ladrillo, es la unidad básica de almacenamiento en GlusterFS, representada por un directorio de exportación en un servidor en el grupo de almacenamiento de confianza.
Creando un clúster con GlusterFS
En este caso, voy a utilizar dos servidores con Rocky Linux en su versión 9, que es última versión a fecha de escribir esta entrada. Las dos son máquinas virtuales que tengo en una computadora de casa. Aunque, como es evidente, en entornos productivos esto debería estar en un entorno como vmWare, proxmox o similares.
La máquina cliente será un Rapbian 11, que además utilizaré para realizar parte del despliegue Ansible.
Finalmente el entorno sería el siguiente:
- servnode1.bitsandlinux.com – 192.168.0.61 (Rocky Linux 9)
- servnode2.bitsandlinux.com – 192.168.0.62 (Rocky Linux 9)
- raspberrypi.bitsandlinux.com – 192.168.0.20 (Raspbian 11)
Es importante que estos datos también los tengamos indicados en el fichero /etc/hosts de las máquinas del clúster, y del cliente:
192.168.0.61 servnode1.bitsandlinux.com servnode1 192.168.0.62 servnode2.bitsandlinux.com servnode2
Preparando los dicos
Lo primero que vamos a hacer es añadir un nuevo disco a ambas máquinas virtuales, en mi caso de 5 GB.
Añadimos el disco adicional de 5GB en cada una de las máquinas virtuales
No es mucho, pero suficiente para esta entrada:
sudo pvcreate /dev/sdb sudo vgcreate vg_data /dev/sdb sudo lvcreate -l 100%F-n lv_data vg_data sudo mkfs. fs /dev/vg_data/lv_data sudo mkdir -p /data/glusterfs/volume1
Bueno, eso sería la parte manual y es lo que está indicado en la documentación oficial. Pero como me gusta jugar, he realizado esta parte utilizando Ansible. Ya que cuando tengamos decenas de nodos, como que hacer estos pasos uno a uno es tedioso y una pérdida de tiempo.
Para ello he creado un Playbook que he subido a mi Github: Playbook para montaje de discos para GlusterFS
Os dejo una imagen del despliegue del Playbook:
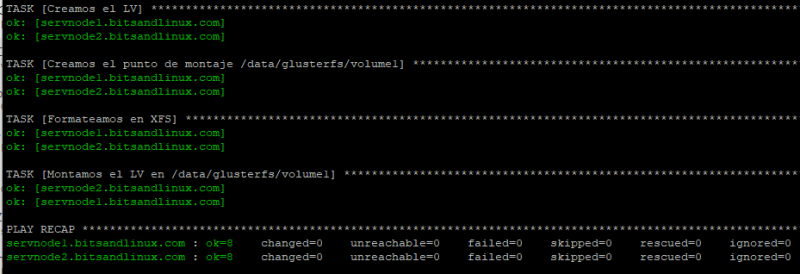
Muestra del despliegue del Playbook de Ansible
Además, si lo hacemos de esta manera no nos hace falta añadir a mano la línea del fstab, que es esta:
/dev/mapper/vg_data-lv_data /data/glusterfs/volume1 xfs defaults 1 2
Así que ya sabéis, aprender Ansible, la vida os será más fácil 😉
Una vez hecho todo esto, como los datos se almacenan en un subvolumen llamado brick, podemos crear un directorio en este nuevo espacio de datos dedicado a él:
sudo mkdir /data/glusterfs/volume1/brick0
Instalación de GlusterFS
Aquí hay que instalar el software necesario de GlusterFS en los dos nodos. Eso sí, hay que tener en cuenta, en el momento de esta entrada, el repositorio original de almacenamiento SIG de CentOS ya no está disponible y el repositorio de RockyLinux aún no está disponible.
Para ello, tal y como indican en la documentación oficial de Rocky Linux, vamos a utilizar el repositorio almacenado.
En primer lugar, es necesario añadir el repositorio dedicado a gluster (en versión 9) en ambos servidores:
sudo dnf install centos-release-gluster9
Puesto que la lista de repos y la url ya no están disponibles, cambiremos el contenido del archivo /etc/yum.repos.d/CentOS-Gluster-9.repo. Simplemente debemos añadir esta línea:
baseurl=https://dl.rockylinux.org/vault/centos/8.5.2111/storage/x86_64/gluster-9/
Ahora sí, ya podemos instalar:
sudo dnf install glusterfs glusterfs-libs glusterfs-server
Configuración del cortafuegos
Se necesitan algunas reglas para que el servicio funcione:
sudo firewall-cmd --zone=public --add-service=glusterfs --permanent sudo firewall-cmd --reload
O bien:
sudo firewall-cmd --zone=public --add-port=24007-24008/tcp --permanent sudo firewall-cmd --zone=public --add-port=49152/tcp --permanent sudo firewall-cmd --reload
Iniciamos los servicios
Vamos a iniciar el servicio:
sudo systemctl enable glusterfsd.service glusterd.service sudo systemctl start glusterfsd.service glusterd.service
Una vez hecho esto ya podemos conectar ambos nodos:
sudo gluster peer probe servnode2.bitsandlinux.com
peer probe: successTambién podemos verificar el estado:
gluster peer status Number of Peers: 1 Hostname: servnode2.bitsandlinux.com Uuid: 21d9be55-ccc0-41f4-9cfc-467ad70a9c37 State: Peer in Cluster (Connected)
Y desde el otro nodo:
gluster peer status Number of Peers: 1 Hostname: servnode1.bitsandlinux.com Uuid: 8c66574a-dad3-47d5-a023-f5702dbfad04 State: Peer in Cluster (Connected)
Ahora podemos crear un volumen con 2 réplicas:
sudo gluster volume create volume1 replica 2 servnode1.bitsandlinux.com:/data/glusterfs/volume1/brick0/ servnode2.bitsandlinux.com:/data/glusterfs/volume1/brick0/
Nos aparecerá un mensaje indicando que un sistema con dos nodos no es la mejor idea, por lo menos deberían ser tres. Pero para realizar esta entrada, al igual que en la guía oficial, no he creído necesario utilizar más nodos.
Ahora ya podemos iniciar el volúmen:
sudo gluster volume start volume1
volume start: volume1: successComprobamos el estado:
sudo gluster volume statusCon este resultado en mi caso:
Status of volume: volume1 Gluster process TCP Port RDMA Port Online Pid ------------------------------------------------------------------------------ Brick servnode1.bitsandlinux.com:/data/glus terfs/volume1/brick0 49152 0 Y 10093 Brick servnode2.bitsandlinux.com:/data/glus terfs/volume1/brick0 49152 0 Y 9575 Self-heal Daemon on localhost N/A N/A Y 9592 Self-heal Daemon on servnode1.bitsandlinux. com N/A N/A Y 10110 Task Status of Volume volume1 ------------------------------------------------------------------------------ There are no active volume task
También podemos obtener una información de volúmen:
sudo gluster volume infoCon el resultado:
Volume Name: volume1 Type: Replicate Volume ID: b29a5a97-0412-4d78-8a35-3e0026f682da Status: Started Snapshot Count: 0 Number of Bricks: 1 x 2 = 2 Transport-type: tcp Bricks: Brick1: servnode1.bitsandlinux.com:/data/glusterfs/volume1/brick0 Brick2: servnode2.bitsandlinux.com:/data/glusterfs/volume1/brick0 Options Reconfigured: auth.allow: 192.168.0.* cluster.granular-entry-heal: on storage.fips-mode-rchecksum: on transport.address-family: inet nfs.disable: on performance.client-io-threads: off
El estado debe ser «Started»
También podemos limitar el acceso indicando la red desde donde se puede utilizar el recurso:
sudo gluster volume set volume1 auth.allow 192.168.0.*
Acceso desde los clientes
Ahora vamos a instalar el software necesario para que desde mi RaspberryPi con Raspbian, pueda acceder al recurso:
sudo apt install glusterfs-client sudo mkdir /datafs sudo mount.glusterfs servnode1.bitsandlinux.com:/volume1 /datafs
De esta forma ya deberíamos poder utilizar el recurso.
Recordar añadir la línea correspondiente en el /etc/fstab del cliente, para poder acceder al FS siempre que se reincie el equipo.
Posibles incidencias
La gracia de este sistema es la alta disponibilidad de la información que alberga.
He creado un fichero llamado «test» en el FS y posteriormente he apagado el nodo 1.
A pesar de esto, al estar arriba el nodo 2, he podido acceder al FS sin problema desde el cliente.
Desde el nodo 2 podemos comprobar que efectivamente el 1 está fuera de línea:
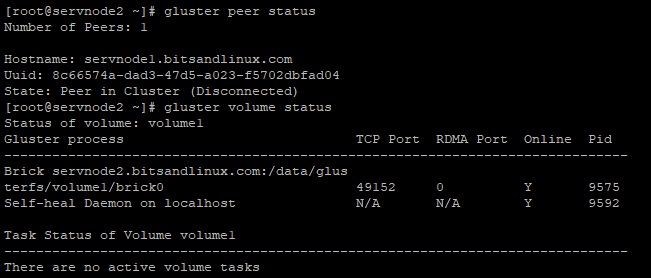
Comprobamos estado de los nodos y volúmenes
De esta forma nos garantizamos que tengamos la información siempre accesible.
Fuentes consultadas
Documentación oficial RockyLinux para Gluster FS
Red Hat – Using Ansible to automate Logical Volume Manager configurations


Hace mucho tiempo que probé GlusterFS por primera vez. Fue para una tienda online, donde tenía los ficheros estáticos replicados en un segundo servidor, eran cerca de 50GB, allá por 2014 y ¡funcionaba como un tiro! Me encantó la estabilidad que tenía porque estuve jugando con los nodos, tirándolos, apagándolos y no se quedaba pillado ni hacía cosas raras (recuerdo una alternativa que se nos ocurrió antes de usar GlusterFS, que era un servidor NFS al que las dos máquinas atacaran para leer/escribir y fue lo más inestable del mundo).
Seguro que tiene muchas novedades y es mucho más estable. (Me ha encantado que pongas el playbook, yo llevo unos años que todo lo relativo a servidores lo hago con playbooks y es una gozada).
hola compañero,
Me alegra verte por aquí. En el trabajo todavía no me he encontrado con ningún entorno con GlusterFS, aún así me ha parecido muy interesante jugar con esta herramienta. Un saludo!!
La verdad que yo estoy intentando y no puedo, me esta siendo imposible configurarlo, lo quiero para un servidor con ISPConfig y me estoy volviendo tarumba… jajajaa A ver si me salgo con la mia.