Filtros en Linux
De vez en cuando viene bien repasar conocimientos básicos, por lo que hoy vamos a hablar de filtros en Linux. Para ello vamos a utilizar las herramientas más comunes de línea de comandos en sistemas UNIX y GNU/Linux. En concreto trataremos con las siguientes herramientas: cut, sort, uniq, wc, tee, head, tail y grep. Todos ellos son comandos básicos.
Cualquier comando con buen comportamiento que lea STDIN y escriba en STDOUT se puede utilizar como filtro de los datos del proceso. Lo conseguimos al utilizar una o varias PIPES, que nos ayudarán a realizar el filtrado deseado.

Filtros en Linux
Comando cut
El comando cut imprime partes seleccionadas de las líneas de entrada. El delimitador predeterminado es tabulador, pero podemos cambiar los delimitadores con la opción -d. El parámetro -f especifican qué campo incluir en la salida.
Veamos una muestra de uso:
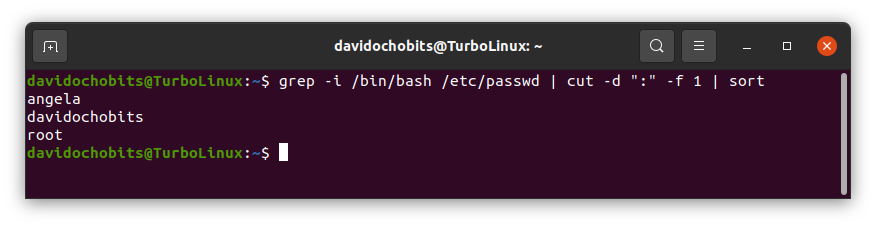
Ejemplo de uso de cut
De esta forma, nos muestra únicamente el resultado de los usuarios del sistema, que utizan bash como interprete de comandos, además ordena los resultados de forma alfabética con el comando sort, que veremos a continuación.
Para conocer más a fondo el comando cut, podéis consultar la entrada que le dediqué hace un tiempo: Ejemplos prácticos del comando CUT en Linux
Comando sort
Este comando se encarga de ordenar las líneas de un texto. Aunque no es tan simple como parece. Digamos que podemos sacar más punta al lápiz, respecto a las partes exactas de cada línea que ordena y el orden final que se impondrá.
Sus opciones son:
- -b Ignora los espacios en blanco.
- -f No distingue entre mayúsculas y minúsculas.
- -k Especifica las columnas que forman la clave de clasificación.
- -n Compara campos con números enteros.
- -r Orden de clasificación inverso.
- -t Establece el separador de campo (por defecto es un espacio en blanco).
- -u Genera registros únicos.
En el apartado anterior sobre cut tenéis un ejemplo de uso.
Comando uniq
Se encarga de imprimir líneas únicas. Su uso es similar a sort -u, pero tiene algunas opciones útiles que sort no emula: -c para contar el número de instancias de cada línea, -d para mostrar solo líneas duplicadas y -u para mostrar solo líneas no duplicadas.
Ejemplo de uso de uniq:
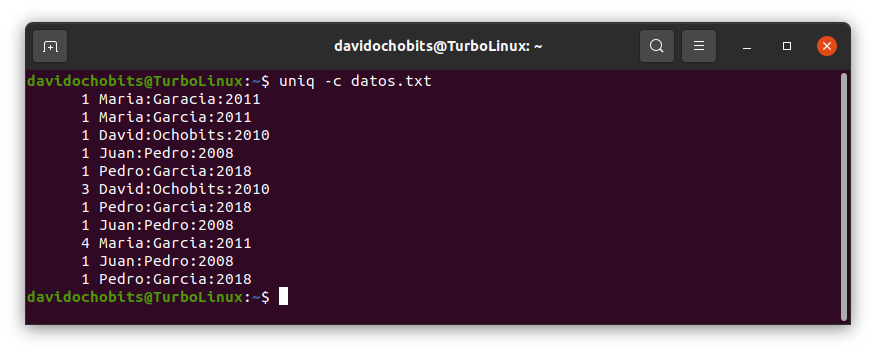
Ejemplo de uso de uniq
Comando wc
Se encarga de contar líneas, palabras y carácteres. Existen una serie de opciones que seleccionan la información que queremos que se imprima. Siempre en este orden: nueva línea, palabra, carácter, byte y longitud máxima de línea.
- -c, –bytes, imprime los recuentos de bytes
- -m, –chars, imprime el recuerto de carácteres
- -l, –lines, imprime el recuento de líneas
- -L, –max-line-length, imprime la longitud de la línea más larga
- -w, –words, imprime el recuento de palabras
Veamos una muestra de su uso:
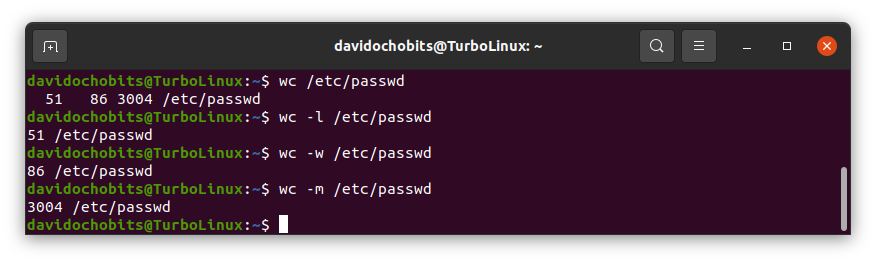
Muestra de uso de wc
Comando tee
Una canalización de comandos suele ser lineal, pero a menudo es útil aprovechar el flujo de datos y enviar una copia a un archivo o a las ventanas de la terminal. Podemos hacer esto con el comando tee, que envía su entrada estándar tanto a la salida estándar como a un archivo dado que especifiquemos en la línea de comandos.
Una forma de uso básico sería:
wc -l file1.txt | tee file2.txt
Este comando comprobará el recuento de líneas del primer archivo y mostrará el resultado en la terminal, y a su vez lo guardará en el segundo archivo.
Comando head y tail
Estos comandos van a la par, se encargan de leer el principio o el final de un archivo. Leer líneas desde el principio o el final de un archivo es una operación administrativa bastante común.
Ambos comandos muestran diez líneas de forma predeterminada, pero podemos inclur parámetros para especificar cuantas líneas queremos ver.
Respecto a otros comandos como less, quizás head esta un poco anticuado; aún asi es todavía muy utilizado en los scripts.
En lo que respecta a tail, en combinación con el parámetro -f es particularmente útil para administradores de sistemas, sobre todo para consultar los ficheros de registros en directo. En lugar de salir inmediatamente después de imprimir el número de líneas solicitado, tail -f, espera a que se agreguen nuevas líneas al final del archivo y las imprime tal y como aparecen.
En su día escribí una entrada al respecto sobre ambos comandos: Uso de los comandos tail y head en Linux
Comando grep
Este popular comando busca un texto de entrada e imprime las líneas que coinciden con un patrón dado. Su nombre se basa en el comando g/regular-expression/p del antiguo editor ed, que venía con las primeras versiones de UNIX
Respecto a las expresiones regulares, podemos decir que se trata de patrones de coincidencia de texto, escritos en un estándar utilizado por la mayoría de los programas que hacen coincidencia de patrones, aunque existen variaciones menores entre las diferentes implementaciones.
Como la mayoría de los comandos en GNU/Linux, grep tiene un buen número de opciones, por ejemplo, con -c podemos imprimir un recuento de líneas coincidentes, con -i se ignoran el uso de mayúsculas y minúsculas en las coincidencias, y con -v se imprimen las líneas que no coinciden. Otro parámetro interesante es -l, que hace que grep imprimma solo los nombres de los archivos coincidentes en lugar de imprimir cada línea.
Para muestra un botón:
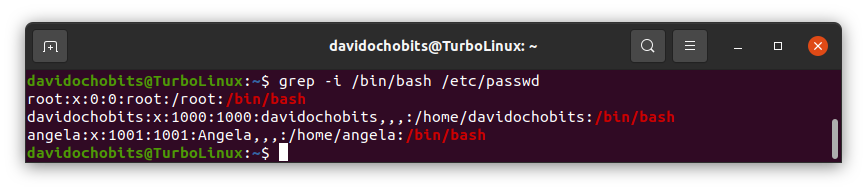
Uso del comando grep
Y esto es todo. ¿Tenéis experiencia con estos comandos? ¿Los utilizáis en vuestro día a día? Podéis dejar vuestras respuestas en los comentarios de más abajo, me gustaría leerlas.


De los mencionados en el artículo he utilizado bastante: grep y tail. Otros que he usado con mayor frecuencia son: cat, tr, sed y awk. Este último combinado con los anteriores me ha sido particularmente útil para filtrar datos estadísticos, una verdadera joya.
Saludos.
Hola colega,
Sí yo también uso esos comandos. Sed y AWK van muy bien para modificar archivos de forma masiva.
Saludos!