Gestión de la configuración con Ansible
Sin duda la gestión de la configuración de un parque informático es clave, para evitar muchos dolores de cabeza. También se suele denominar a este proceso como automatización de TI y orquestación de servidores. Sea como fuere, lo que se busca son los aspectos prácticos de la gestión de la configuración y la capacidad de controlar varios sistemas desde un servidor central.
Ya he hablado más de una vez de como Puppet nos puede ayudar con la gestión de la configuración de un parque informático. El problema que tiene Puppet, es que parece que últimamente se le está relegando a un segundo plano, en beneficio de Ansible. Ya sea por simple moda o bien porque Ansible tiene una ventaja bastante importante respecto a su competidor, y es que la herramienta de Red Hat no necesita instalación de agente. De hecho, con un intercambio de llaves vía SSH hay más que suficiente, como ya os expliqué, para conectar clientes a nuestro servidor central.
Recordar que todos los hosts con los que trabajo son VPS ubicados en mi empresa de confianza Clouding.io, ubicado en mi ciudad, Barcelona.
![]()
Gestión de configuración con Ansible
Algunos beneficios de las herramientas de gestión de configuración
Esta entrada no pretende ser un artículo sesudo al detalle sobre las ventajas de la gestión de configuración, pero sí podemos dar algunas pinceladas:
- Podemos utilizar un sistema de control de versiones, para realizar un seguimiento de cualquier cambio en la infraestructura, ya sea física o virtual.
- Permite reutilizar los guiones o scripts de aprovisionamiento para múltiples entornos, como por ejemplo desarrollo, calidad o producción.
- Se garantiza tener un sistema fiable, con unos patrones que deben seguir las configuraciones de todos los entornos.
Todo ello controlado desde un servidor central, ya sean un puñado de servidores o miles de ellos.
¿Cómo empezar con Ansible?
En la web ya hemos hablado muchas veces de Ansible y cómo empezar con él. Aquí os dejo las entradas donde os explico en qué consiste Ansible y cómo empezar a trabajar con él:
- ¿Qué es Ansible? ¿Para qué sirve?
- Instalación de Ansible en GNU/Linux
- Primeros pasos con Ansible
- Crear nuestro primero Playbook con Ansible
Todo controlado
Ansible realiza un seguimiento del estado de los recursos en los sistemas administrados para evitar repetir tareas que se ejecutaron antes. Por ejemplo, si ya instalamos un paquete, Ansible no intentará volver a instalarlo. El objetivo es que, después de cada ejecución de aprovisionamiento, el sistema alcance (o mantenga) el estado deseado, incluso si lo ejecuta varias veces. En esto Puppet y Ansible coinciden en efectividad.
Recopilando datos del sistema
Ansible recupera información detallada de todos sus clientes, como las interfaces de red o las versiones del sistema operativo, por poner algunos ejemplos. Estos datos se añaden como variables globales llamadas “Facts” del sistema. Estos “Facts” se pueden usar dentro de los libros de jugadas (Playbooks), para así hacer que la automatización sea más eficiente y varie según el sistema que aprovisione.
Un sistema de plantillas
Ansible utiliza una serie de plantillas para facilitar la configuración de archivos y servicios. Estas se basan en plantillas Jinja2 de Python, que permiten expresiones dinámicas y acceso a variables.
Soporte para extensiones y módulos
Si habéis echado un vistazo a los enlaces que os he indicado antes, habéis podido ver como Ansible utiliza cientos de módulos integrados, para facilitar la automatización de tareas comunes de administración de sistemas. Además de los integrados también se pueden encontrar módulos en Ansible Galaxy o bien crearlos nosotros mismos.
Con la manta en la cabeza
Bien, ahora que hemos visto un poco en qué consiste eso de la gestión de configuración, veamos algunos ejemplos.
Configuración DNS
Vamos a ver cómo provisionar el fichero de configuración “resolv.conf”, para que todos los hosts que nosotros decidamos siempre tengan el mismo fichero.
Para ello nos iremos al servidor central, y dentro de la carpeta “roles” añadiremos una serie de ficheros, para que quede de la siguiente manera:
pi@raspberrypi:/etc/ansible/roles $ tree . └── resolv.conf ├── handlers │ └── main.yml ├── tasks │ └── main.yml └── templates └── resolv.conf.j2 4 directories, 3 files
Sobre el fichero tasks/main.yml
Para poder administrar el archivo /etc/resolv.conf con Ansible, primero hay que impedir que NetworkManager lo haga. Para esta tarea, utilizamos el módulo ini_file de Ansible, que establece la opción requerida dns=none en la sección [main]
Quedando así:
--- - name: nos aseguramos que la línea 'dns=none' esté configurada en /etc/NetworkManager/NetworkManager.conf ini_file: path: /etc/NetworkManager/NetworkManager.conf state: present no_extra_spaces: yes section: main option: dns value: none owner: root group: root mode: 0644 backup: yes notify: - reload NetworkManager
La segunda tarea utiliza el módulo de plantilla, para crear la configuración de destino, a partir del contenido de roles/resolv.conf/templates/resolv.conf.j2 y colocarlo en /etc/resolv.conf en el nodo de destino:
--- - name: deploy resolv.conf template template: src: roles/resolv.conf/templates/resolv.conf.j2 dest: /etc/resolv.conf owner: root group: root mode: 0644 backup: yes notify: - reload NetworkManager
La plantilla contiene un texto estático. Podríamos haber usado el módulo de copia para copiar este archivo en el nodo de destino. Sin embargo, utilizamos el módulo de plantilla, para mantener abierta la posibilidad de crear el contenido de forma dinámica, mediante el uso de variables.
Con notificación: un controlador llamado recargar NetworkManager se llama dos veces en este libro de jugadas. Cubriremos los controladores en la siguiente sección.
Sobre el fichero handlers/main.yml
Los controladores (conocidos como handlers) se utilizan para desencadenar acciones que solo se ejecutan si una tarea realiza cambios en el nodo de destino. Estos controladores solo se procesan al final de un libro de jugadas y solo se ejecutan una vez, incluso si varias tareas les notificaron los cambios.
En el ejemplo descrito en esta pequeña guía, el controlador denominado reload NetworkManager ejecuta la tarea definida, pero solo si una de las dos tareas (o ambas) de tasks/main.yml ha provocado un cambio en el nodo de destino:
El contenido de resolv.conf/handlers/main.yml es:
---
- name: reload NetworkManager
service:
name: NetworkManager
state: reloadedUna vez hecho esto. Veamos si al ejecutar todo funciona bien.
Para ello voy a utilizar un grupo de hosts, que tengo con Rocky Linux 8, para ello he creado el siguiente Playbook, llamado «deploy-role-dns.yml», con el contenido:
- hosts: VPS-ROCKY
become: true
roles:
- resolv.confTengo intercambio de llaves con los hosts con un usuario diferente de «root», que pertenece al grupo «wheel«, esto es «sudo«. Por lo que le indico, con «-K«, que me pida la contraseña, aquí tenéis el resultado al ejecutar ansibleplaybook deploy-role-dns.yml -K":
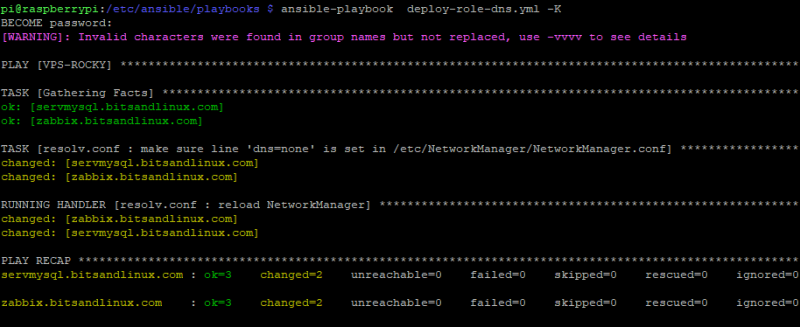
Desplegamos el rol vía Playbook de Ansible
Y esto es todo. Bueno, por lo menos una entrada para el mes de junio de este año 2023, que no es nada 🙂
Fuentes consultadas
DNS configuration with Ansible
Missing sudo password in Ansible
Libros recomendados sobre Ansible
Ansible: Up and Running, 3rd Edition de editorial O’Reilly (en inglés)
Libro que yo tengo y que siempre os recomiendo, además está en castellano:


Comentarios Recientes