Alta disponibilidad con clúster en Centos 7
En esta entrada vamos a ver como montar un clúster de alta disponibilidad, en sus siglas HA, de su nombre en inglés “High Availability”, en un servidor con Centos 7. De esta manera podemos ver su instalación, configuración y mantenimiento.
Hay que tener en cuenta que un clúster, en computación, está formado por dos o más nodos, que trabajan juntos para realizar cierta tarea. De esta manera si uno de los nodos falla el otro nodo seguirá suministrando el servicio.
Alta disponibilidad con clúster en Centos 7
Los clústeres pueden ser de diferentes tipos:
- De Almacenamiento: proporciona una imagen del sistema de ficheros coherente, a través de los servicios suministrados por el clúster, permitiendo que los servidores lean y escriban simultáneamente en un solo de ficheros compartido.
- Alta disponibilidad: elimina los puntos únicos de fallo y conmuta los servicios ante un error en unos de los nodos.
- Equilibrio de carga: envía solicitudes de servicio de red a varios nodos del clúster para equilibrar la carga de solicitud entre los nodos.
- Alto rendimiento: realiza un procesamiento en paralelo o simultaneo, lo que ayuda a mejorar el rendimiento de las aplicaciones.
Otra solución ampliamente utilizada para ofrecer HA es la replicación (específicamente la replicación de datos) La replicación es el proceso mediante el cual una o más bases de datos (secundarias) se pueden mantener sincronizadas con una única base de datos principal (o maestra)
Para este artículo utilizaremos dos nodos, con los nombres:
- Nodo 1: servnode1 con IP 192.168.0.150
- Nodo 2: servnode2 con IP 192.168.0.151
Crearemos un clúster activo – pasivo, con una IP virtual y un servicio de web de Apache.
Pasos previos
Para evitar posibles problemas vamos a deshabilitar SELinux, editando su fichero de configuración:
vi /etc/selinux/config
Y sustituir:
SELINUX=enforcing
Por:
SELINUX=disabled
Guardamos y salimos.
Para que se apliquen los cambios debemos reiniciar.
Además, deshabilitamos el cortafuegos para simplificar las cosas:
systemctl disable firewalld
systemctl stop firewalld
Configurar el DNS local
Para que las dos máquinas se puedan comunicar entre sí se debeconfigurar el DNS local, mediante la configuración del fichero “/etc/hosts”, en ambos nodos.
vi /etc/hosts
Y añadimos:
192.168.0.150 servnode1.localdomain servnode1
192.168.0.151 servnode2.localdomain servnode2
Guardamos y salimos con : “:wq”
Instalar el servidor Web Apache
La instalación es bien sencilla, para instalar Apache:
yum -y install httpd
Esto, al igual que el resto de los pasos, se tienen que hacer en ambos nodos.
Además vamos a crear un fichero de configuración que nos muestra el estado del servidor Apache:
vi /etc/httpd/conf.d/status.conf
Con el contenido:
<Location /server-status>
SetHandler server-statusOrder Deny,AllowDeny from all
Allow from 127.0.0.1
</Location>
Estas directivas permiten el acceso a la página de estado solamente desde localhost del nodo activo.
Instalamos y configuramos Corosync y Pacemaker
Las piezas esenciales para el funcionamiento del clúster con Corosync, que nos provee del engine del clúster; con Pacemaker obtendremos las funciones básicas para que el grupo de nodos trabajen juntos en el clúster.
Instalación de Corosync, Pacemaker y pcs
Debemos ejecutar el siguiente comando:
yum install corosync pacemaker pcs
Una vez instalados nos debemos asegurar que la pieza pcs este encendida y añadido al arranque:
systemctl enable pcsdsystemctl start pcsd
systemctl status pcsd
Creamos el clúster
Durante la instalación se crea un usuario del sistema llamado “hacluster” Así que necesitamos asignarle una contraseña necesaria para la pieza “pcs” De la siguiente manera, en ambos nodos:
passwd hacluster
Una vez hecho esto, desde el nodo 1, ejecutamos el siguiente comentado:
[root@servnode1 ]# pcs cluster auth servnode1.localdomain servnode2.localdomain -u hacluster -p contrasea --force
servnode2.localdomain: Authorized
servnode1.localdomain: Authorized
Ahora ya podemos crear el clúster, con el nombre que deseemos, aunque no puede superar los 15 caracteres.
Con el comando:
pcs cluster setup --name nombre-que-deseemos servnode1.localdomain servnode2.localdomain
En mi caso:
[root@servnode1 /]# pcs cluster setup --name clusterweb servnode1.localdomain servnode2.localdomain
Destroying cluster on nodes: servnode1.localdomain, servnode2.localdomain...
servnode1.localdomain: Stopping Cluster (pacemaker)...
servnode2.localdomain: Stopping Cluster (pacemaker)...
servnode2.localdomain: Successfully destroyed cluster
servnode1.localdomain: Successfully destroyed cluster
Sending 'pacemaker_remote authkey' to 'servnode1.localdomain', 'servnode2.localdomain'
servnode2.localdomain: successful distribution of the file 'pacemaker_remote authkey'
servnode1.localdomain: successful distribution of the file 'pacemaker_remote authkey'
Sending cluster config files to the nodes...
servnode1.localdomain: Succeeded
servnode2.localdomain: Succeeded
Synchronizing pcsd certificates on nodes servnode1.localdomain, servnode2.localdomain...
servnode2.localdomain: Success
servnode1.localdomain: Success
Restarting pcsd on the nodes in order to reload the certificates...servnode2.localdomain: Success
servnode1.localdomain: Success
Ahora ya Podemos añadir el clúster al arranque y encenderlo:
pcs cluster enable –allpcs cluster start –all
Tal como sigue:
[root@servnode1 /]# pcs cluster start --all
servnode1.localdomain: Starting Cluster (corosync)...
servnode2.localdomain: Starting Cluster (corosync)...
servnode1.localdomain: Starting Cluster (pacemaker)...
servnode2.localdomain: Starting Cluster (pacemaker)...
[root@servnode1 /]# pcs cluster enable --all
servnode1.localdomain: Cluster Enabled
servnode2.localdomain: Cluster Enabled
Podemos comprobar su estado, de las siguientes maneras:
pcs status
crm_mon -1
Una muestra en mi caso:
[root@servnode1 /]# sudo pcs status
Cluster name: clusterweb
WARNINGS:
No stonith devices and stonith-enabled is not falseStack: corosync
Current DC: servnode1.localdomain (version 1.1.19-8.el7_6.2-c3c624ea3d) - partition with quorum
Last updated: Thu Dec 20 10:37:37 2018
Last change: Thu Dec 20 10:33:38 2018 by hacluster via crmd on servnode1.localdomain
2 nodes configured0 resources configuredOnline: [ servnode1.localdomain servnode2.localdomain ]
No resources
Daemon Status:
corosync: active/enabledpacemaker: active/enabledpcsd: active/enabled[root@servnode1 /]# crm_mon -1
Stack: corosync
Current DC: servnode1.localdomain (version 1.1.19-8.el7_6.2-c3c624ea3d) - partition with quorum
Last updated: Thu Dec 20 10:37:48 2018
Last change: Thu Dec 20 10:33:38 2018 by hacluster via crmd on servnode1.localdomain
2 nodes configured0 resources configuredOnline: [ servnode1.localdomain servnode2.localdomain ]
No active resources
De esta manera observamos que los dos nodos están conectados, sin errores y en línea. Aún así se nos muestra la siguiente advertencia “No stonith devices and stonith-enabled is not false”, esto es debido a que no hemos definido el STONITH, que se encarga de realizar “fence”, también conocido como “te pego un tiro en la cabeza”, cuando uno de los nodos no funciona correctamente. Todavía nos queda más trabajo por delante, ya que tampoco hemos definido servicios.
Configurar las opciones del clúster
Como hemos dicho la pieza del STONITH esta habilitada por defecto, pero en esta guía no lo vamos a utilizar, por lo que lo vamos a deshabilitar.
Deshabilitamos STONITH :
pcs property set stonith-enabled=false
Además, indicamos que vamos a ignorar la política de cuórum:
pcs property set no-quorum-policy=ignore
Para asegurarnos que todo esta correcto, y que tanto el STONITH como la política de cuórum están deshabilitados:
[root@servnode1 /]# pcs property list
Cluster Properties:
cluster-infrastructure: corosync
cluster-name: clusterweb
dc-version: 1.1.19-8.el7_6.2-c3c624ea3dhave-watchdog: falseno-quorum-policy: ignore
stonith-enabled: false
Añadir un nuevo servicio o recurso al clúster
En este apartado veremos como agregar un nuevo recurso a nuestro clúster. Una parte importante es configurar una IP virtual, llamada VIP, que se podrá mover de manera instánea de un nodo a otro dentro de la misma red o centro de datos. Necesitamos que esta VIP la utilice el nodo que en ese momento sea el activo.
Por lo que vamos a añadir dos recursos, uno será la VIP y el otro será el webserver con Apache.
Añadimos la siguiente la 192.168.0.160 como VIP, ejecutando la siguiente orden:
pcs resource create vip ocf:heartbeat:IPaddr2 ip=192.168.0.160 cidr_netmask=24 op monitor interval=60s
Analicemos las partes del comando:
- vip: Es el nombre del recurso
- “ocf:heartbeat:IPaddr2”: Le indicamos a pacemaker que script debe utilizar, IPaddr2 en este caso. Además definimos en que espacio de nombre se encuentra (pacemaker) y que estandar utiliza, que ese «ocf»
- “op monitor interval=60s”: Indica a pacemaker que verifique la salud del servicio cada minutos, esto es, 60 segundos.
Ahora que ya tenemos la IP de la VIP definida, pasamos a añadir el servicio web.
pcs resource create servicio_http ocf:heartbeat:apache configfile=/etc/httpd/conf/httpd.conf \
statusurl="http://127.0.0.1/server-status" op monitor interval=20s
Una vez añadidos ambos servicios. Los comprobamos:
pcs status resources
En mi caso:
[root@servnode1 conf]# pcs status resources
vip (ocf::heartbeat:IPaddr2): Started servnode1.localdomain
servicio_http (ocf::heartbeat:apache): Starting servnode2.localdomain
En cuanto a la salida del comando, se han enumerado los dos recursos agregados: «vip» y «servicio_http». Cada uno de los servicios están, en mi caso, en nodos diferentes.
A mi me interesa que tanto la VIP como al servicio de Apache estén en el mismo nodo.
Configuración de parámetros de INFINITY
Casi todas las decisiones en un grupo de pacemaker, como elegir dónde se debe ejecutar un recurso, se realizan comparando una serie de puntuaciones. Las puntuaciones se calculan por recurso, y el administrador de recursos de clúster elige el nodo con la puntuación más alta para un recurso en particular. (Si un nodo tiene una puntuación negativa para un recurso, el recurso no se puede ejecutar en ese nodo).
Podemos manipular las decisiones del clúster con restricciones. Las restricciones tienen una puntuación. Si una restricción tiene una puntuación inferior a INFINITY, es solo una recomendación. Una puntuación de INFINITY significa que es una necesidad.
Queremos asegurarnos de que ambos recursos se ejecuten en el mismo host, por lo que definiremos una restricción de colocación con una puntuación de INFINITY.
pcs constraint colocation add servicio_http vip INFINITY
De esta manena ya tenemos ambos recursos en el mismo host:
Full list of resources:
vip (ocf::heartbeat:IPaddr2): Started servnode2.localdomain
servicio_http (ocf::heartbeat:apache): Started servnode2.localdomain
Pruebas de funcionamiento del clúster
Vale, todo esto está muy bien, ¿pero funciona? Desde la consola de comandos, mediante el prograna «Lynx«, consultaremos el estado:
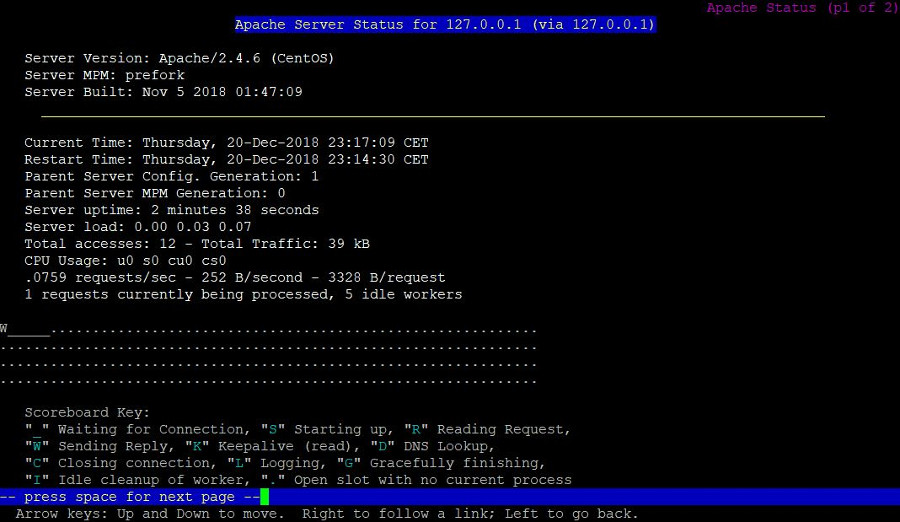
Consulta de estado utilizando Lynx
Hay que anotar que el servicio web de Apache ahora está gestionado directamente por el clúster. Podemos comprobar que esto es así, en el nodo activo:
[root@servnode2 conf.d]# lsof -i :80
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAMEhttpd 5871 root 4u IPv6 32431 0t0 TCP *:http (LISTEN)
httpd 5872 apache 4u IPv6 32431 0t0 TCP *:http (LISTEN)
httpd 5873 apache 4u IPv6 32431 0t0 TCP *:http (LISTEN)
httpd 5874 apache 4u IPv6 32431 0t0 TCP *:http (LISTEN)
httpd 5875 apache 4u IPv6 32431 0t0 TCP *:http (LISTEN)
httpd 5876 apache 4u IPv6 32431 0t0 TCP *:http (LISTEN)
NOTA: Es muy importante que no intentemos gestionar el servicio de httpd directamente, ya que todas las gestiones se tienen que realizar a través del propio clúster.
Y esto es todo por hoy. Espero que os haya parecido interesante. ¿Tenéis experiencia con la gestión de clústers? Podéis dejar vuestras opiniones en los comentarios.
Nos vamos leyendo.
Fuentes consultadas:
Tecmint – Setup High Availability clustering in Centos and Ubuntu
DigitalOcean – How to set up an Apache active passive cluster using pacemaker on Centos 7


Que tal, me ha resultado útil tu tutorial pero como consulto que el servicio efectivamente esta siendo gestionado por el cluster en Lynx?
Bueno el artículo es casi igual a uno que vi en ingles, tengo una pregunta: cómo haría si en mi servidor principal tengo una app con php y mysql?
Hola,
Existen muchas entradas similares en la red. Las fuentes que he consultado las tienes al final, por si les quieres echar un vistazo.
Saludos